Life expectancy is the mean number of years someone is expected to live if conditions would remain the same in the future as they are in the current year. But because life expectancy is slightly skewed to the left, David Spiegelhalter calculated that median life expectancy is about three years longer than the mean. That means that most people should expect to live longer than their life expectancy as it is usually calculated.
It’s well-known how misleading it can be to use average (mean) as a summary measure of income: …a few very rich people can hopelessly distort the mean. So median (the value halfway along the distribution) income is generally used, and this might fairly be described as the income of an average person, rather than the average income.
But, like everyone else dealing with actuarial statistics, I use life expectancy (the mean number of future years) to communicate someone’s survival prospects. And yet, just as for income, it is also a poor measure due to the skewness of the distribution of survival.
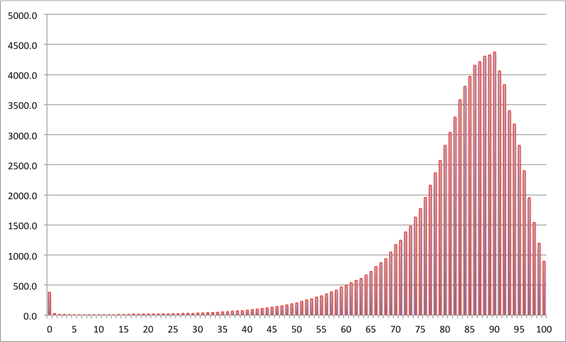
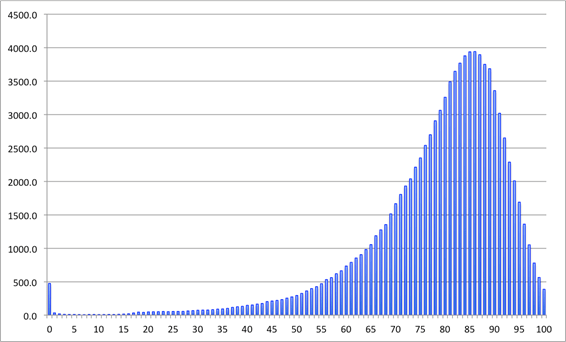
This can be clearly shown by looking at the life tables published by the Office for National Statistics (ONS) …[with] the expected number of deaths at each age out of 100,000 births, assuming the current mortality rates continue. The density plots for women and men are shown below, using the life tables for 2010-2012. The distributions have a small peak for babies dying in the first year of life, and then a long left-tail for early deaths, and then a sharp peak and a rapid fall up to age 100. The ‘compression’ of mortality is clear.
Numbers of women expected to die at each age, out of 100,000 born, assuming mortality rates stay the same as 2010-2012. The expectation is 83, median 86, the most likely value (mode) is 90.
Numbers of men expected to die at each age, out of 100,000 born, assuming mortality rates stay the same as 2010-2012. The expectation is 79, median 82, the most likely value (mode) is 86.
Left-skewed distributions are rather unusual, but have similar issues as any skew distribution – the mean, median and mode can be very different. For these survival distributions it is perhaps remarkable how far the mode is from the mean: for girls born now, even assuming there are no more increases in survival, their most likely age to die is 90, seven years more than the mean on 83. For little baby boys the mode is 86, again seven years more than the mean of 79. And even the median is 3 years more than the mean. That’s why I now believe that ‘life expectancy’ is misleading.
In the comments, Nick Ergodos* opines that:
I think the median beats the mean at every level and for all practical purposes, not only for estimating life expectancy or income. For large sample sizes (or if you repeat the experiment many times) the median approaches the mean anyway so nothing is lost by replacing the mean by the median everywhere. We use the average routinely for historical reasons only, not really for any rational reasons.
I don’t agree with Nick that the median always beats the mean, but it certainly does for income. The best statistic depends upon how it is used and there is no use where mean income is better (unless you are using the mean of log income which produces results that are a rough approximation of the median anyhow). For life expectancy, both measures have different advantages. The median is more realistic for most people (obviously) who have already survived past youthful mortality and gives a better picture of how many years of life they have left. But as a measure of social wellbeing, I’m fine with using mean life expectancy because it gives more weight to the tragedy of youth mortality than median life expectancy does. Most of the increase in (mean) life expectancy over the past two centuries has been due to a reduction in youth mortality and median life expectancy wouldn’t reflect that incredible gain in human wellbeing.
The difference between why mean life expectancy is OK and mean income isn’t OK for measuring welfare (utility) is that a mean assumes constant marginal utility. It is more reasonable to assume that each year of life gives about the same amount of utility than to assume that every dollar of income gives exactly the same amount of utility. That is the philosophical reason why I use standard (mean) life expectancy for calculating MELI rather than median life expectancy. The other reason is practical. As I discovered at the IARIW conference in Korea, it is hard enough to get economists interested in using median income and it would be a harder sell to get them to also switch to median life expectancy. Fortunately, the ordinary way of calculating life expectancy is just fine as a measure of wellbeing even though it isn’t as good for estimating how long you have left to live.
Of course there is only a three year gap between the two measures today, so there isn’t a large difference, but in the late 19th century, the gap was ten years because child mortality was much bigger. And median life expectancy is better for retirement planning. People tend to underestimate their lifespans (especially women) and this may be part of why people do not save enough money for retirement. This is understandable when mean life expectancy underestimates life expectancy for most people and it is THE ubiquitous measure of lifespan. Even the Social Security Administration uses the wrong measure for its retirement planning longevity calculator and if anything, longevity has tended to increase over time (until the crisis of the last three years in the USA), so the period life expectancy has consistently underestimated actual cohort life expectancy for almost two centuries. And if you really want to predict your individual life expectancy, you can get a much better prediction by including risk factors. People who earn more than the median income live a lot longer than poorer people in the US. Other strong predictors include more education, being female, and health and family histories. Life insurance corporations have spent a lot of money on proprietary models that predict how long you will live, but unfortunately most of their research is secret.
*For the wonkish, Nick Ergodos further explains his theory in a published paper that makes a more limited claim about the virtues of the median. It focuses on expected value and argues that the median probability of a gain (or loss) should be used (and is used my most people) for deciding whether or not to make a series of bets rather than the probability-weighted mean (which is the expected value). It is an intriguing theory, but I don’t think it is completely specified for the domain where it works versus where it doesn’t.














Thank you for taking the time reading my paper, and sorry for not being clear about the scope of the theory. I will try to clarify it better below.
If my arguments are correct, the median is always superior to the mean, in particular for single cases with a skewed distribution. Mortality tables are skewed so for a single patient the median is the best predictor. However, if we consider a large group of people the overall median for the group will be extremely close to the mean. This is because the median always approaches the mean when repeating a random experiment indefinitely, as explained in the paper. (Considering a group of n people is mathematically the same as repeating a single random experiment n times.)
This is why actuaries and casino owners always have been content with using the mean when calculating premiums and gamble fees. They are interested in the behaviour of large numbers of insured people or large numbers of repeated gambles, so in their cases the exact medians will be indistinguishable in value from the corresponding means. As the mean is mathematically so much easier to calculate than the exact median for a large number of random experiments, actuaries and casino owners will continue to use the mean for all practical purposes.
If a distribution isn’t skewed at all, the median and the mean will coincide in value, even for single cases. So in these cases it is also safe to use the mean instead of the median.
But just because the median and the mean sometimes coincide in value doesn’t mean that they are the same conceptually. In the paper I try to argue that conceptually it is always correct to use the median instead of the mean. That they happen to coinside numerically in some cases is irrelevant conceptually. Further, that one of them is much easier to calculate in some cases when they lead to almost the same numerical results anyway, is also irrelevant conceptually.
Hope these comments clarify the scope of the theory somewhat better than my paper managed to do.
Thanks Nick. I like your paper, but its been a while since I read it, and I’m on the road in Guatemala with a bunch of final grading due this week, so I’ll have to take more time to give the reply you deserve. I agree with most of your arguments, and it makes a lot of sense that the mean has often been preferred due to its relative ease of calculation rather than for its metrical virtues, but I think there are some special cases where the mean is the preferred statistic even when it isn’t just a matter of being easier to manage mathematically. I’ll try to make a case when I get more time in two weeks…
Thank you Jonathan! I read the paper again and there are indeed many parts that can be explained much better. I had to keep the paper as short as I could, that is my only excuse. However, I look forward to this discussion with you and I hope it will give me an opportunity to explain some of the obscure parts in more detail.
It’s frustrating to me that the mean is used so often as a measure of central tendency in public life where it’s totally inappropriate. A lot of it must be the greater difficulty of calculating mediums in many cases. But where a distribution has a significant skew it would be better to hold off until a median can be calculated.
I live in South Africa – which has the most skewed income distribution on Earth – and the GDP per capita figure is grossly misleading due to the high incomes of a very few. And yet it still affects policy and public perception.
Good points. I agree that it is harder to calculate medians, but I think that is in large part due to the path dependence of history. We have a long history of focusing on doing analysis using means and as a result, our curricula, statistical packages, and data collection methods are biased towards making it easier to do analysis based on means, but it isn’t inherently difficult to calculate a median. In many ways it is much easier to calculate a median. In particular, it should be much easier to estimate median income accurately than to mean income. I wrote a little about that here: https://medianism.org/medianism/faq/m7-what-are-ways-in-which-meli-is-easier-to-measure-than-gdp/
By the way, sorry for the late reply. I’ve been on vacation!
It’s not that difficult to include a good support for calculating medians in statistical software packages. Only the first few medians in a repeated experiment have to be calculated exactly and the rest can be found approximately using Gombauds’s principle as explained in the paper referenced above.
The difficulty to calculate the median isn’t the issue, I think. It’s more the philosophical and historical bias towards viewing means and not the median as the correct predictor that is the issue.
Maybe we should start an open source project for the development of math algorithms and computer code for calculating medians?
[…] we used median life expectancy rather than mean, this would look slightly different, but (almost) nobody uses that […]
I think means are actually better than medians, it’s just that most of the time the wrong thing is being measured. Like, if you care about how likely someone is in a country to experience hunger, you do not care about the ratio of mean, median, or mode GDP per capita to food price unless you believe starvation is the norm in that country and survival is the exception. You instead care much more about the mean income-derived probability of hunger. So you want sensitivity to outliers but not to high income outliers since they barely affect the rate of malnutrition in the country. Instead you want strong sensitivity to low income outliers because people who starve are much more likely to be low income and people who have low income are much more likely to starve.
This will be true in many cases where the main concern is whether or not some need is being met. Even if that need is not actually necessary. You could just as easily derive a probability function of income for private car ownership, or private jet ownership capability for that matter, although attempting to maximize the rate of private jet ownership through economic manipulations is probably some kind of crime against humanity.
I agree that a mean can sometimes be better than a median, such as when data is particularly lumpy as when there are very few data points, but I think that is rarely the case for real-world datasets. More often the median would be better or just as good and it is almost never used, so as a rule of thumb, we should be using medians a lot more often.
My claim is even stronger than just a recommendation to use the median more often than currently used. As outliers are randomly distributed in any sample the habit of using the sample average will lead to randomly scattered and misleading results. The average is not a stable statistic in general. The median is.
In science we believe that taking a larger sample size leads to a better and more accurate measurement than takin a smaller sample size. However this is not the case in general if we stick to taking the sample mean.
So everyone that want to be scientific should switch to the median and abandon the old habit of taking means. In a forthcoming paper I will explain this in more detail.
Nick, I’m looking forward to the new paper! You are doing good work on this and I think that probably 95% of the time a median works better (or at least as well as) a mean. I hate to say this since I completely support your work, but I do think there are a couple instances where a mean can work better. First of all, sometimes a sample median has a larger standard error than the sample mean, such as for very small samples and particularly when the median has an odd number of observations because with an even-number of observations we take the mean of the middle two observations which reduces the standard error a bit – which shows how the mean reduces standard error!
In the history of statistics, I suspect that this advantage helps explain why the mean was favored by early statisticians because they were more commonly working with very small samples. Today however, we live in the era of big data! Plus, sorting data for large samples used to be more computationally difficult than adding and dividing, so it was historically harder to calculate the median than the mean, but today, computers do it easily.
Secondly, occasionally there are times when we want to put more priority on outliers than on the central tendency and in those occasions, the mean is better because it puts more weight on outliers. For example, whenever we care about the total sum as much as the central tendency, then the mean is better because we can multiply the mean times the sample size to get the total. For example, for-profit businesses care equally about every dollar and will often prefer means which value each dollar from outlier customers as much as dollars from average customers. However, when we want a measure of central tendency it is because we care more about the central tendency than about the outliers and the median is a better measure of central tendency with asymmetrical distributions (and about as good for symmetrical distributions depending on how much the standard error is different), and I think this is your point, so keep up the good work.