Updated Feb/25/2023
There are only two possible ways to get wealth inequality: some people either make more or they take more. Making is positive sum creation and taking is zero-sum redistribution at best or destructive at worst. Plus there are also two other important kinds of economic interactions for society. The opposite of taking is not making but giving and without giving, humans would not exist because giving is the foundation of the family, and without families, humans would have died out as a species. Furthermore, the main foundation of the wealth of nations is reciprocating.
Everyone starts life as a taker
It is a fact of biology that all parents are givers and all children are takers in all species that reproduce. Human children are especially needy as they grow up. Few species take more resources as they develop into adults than humans. Ernest Thompson Seton’s father gave him an invoice on his 21st birthday for every penny the family had spent on Ernest including the fee charged by the doctor who delivered him. The total bill for Ernest’s childhood added up to $537.50 which was a princely sum for a penniless young man. The year was 1882, and updating for inflation, in 2023 that would be about $16,000. This bill motivated Ernest to leave his family and, according to some accounts, he never spoke to his father again. Ernest was indignant but compared to the average explicit cost of raising children today ($310,605), Ernest could have considered himself lucky that his father thought he owed so little.
The purest example of a maker (who neither gives nor takes) is an isolated hermit
Once a person is old enough to be self-sufficient, it is possible to live without giving nor taking, but it is extremely rare for anyone to be able to exist for more than a few weeks without economic interactions. The purest maker is the sort of pure hermit who lives alone without interacting with anyone has to make all the wealth he acquires. There are very, very few examples of people who lived the life of a pure maker for more than a year. One of the few documented examples is the famous “Lone Woman of San Nicolas Island” who lived alone on an island for 18 years after the rest of her tribe was wiped out.
Another challenge for pure makers is the fact that everyone, including hermits, is a taker of natural resources. We all consume natural resources that we cannot make. It is possible that an isolated hermit might only take natural resources that nobody else wants. Many philosophers of property rights justify the taking of unwanted resources on the theory that they would otherwise just get wasted. So if a hermit never takes natural resources in a way that prevents anyone else from using them, then an isolated hermit would not be a taker in this sense.
Very few people in history have ever lived self-sufficiently like a pure hermit for more than a few months at a time because it is a life of poverty, risk, and loneliness. Plus, even those who manage to live as hermits for years without interacting with anyone else are not really pure makers because everyone is a taker in childhood. Everyone develops a massive deficit on the karmic balance sheet when growing up, so a hermit that does not give back to society is a massive net taker over his lifespan.
So nobody can be a pure maker and few people ever even try for short periods of time.
The purest examples of a taker
Whereas it is impossible for anyone to be a pure maker for life, and rare for anyone to be a pure maker even for short periods of time, being a pure taker is much easier. We all start out life as pure takers and we can all think of people who manage to live their entire lives without making much of anything for anyone else. Taking comes naturally in childhood and most people gradually reciprocate more and more until they become adults. Indeed, adulthood in traditional societies is typically seen as the transition out of being a net taker.
There are two kinds of takers, the lucky taker and the evil taker. Someone who is lucky enough to take the willing gifts of givers is a lucky taker and we are all lucky takers at times because everyone is a lucky taker in childhood. Some of us are born into situations that are much luckier than others, but nobody would survive without being a lucky taker.
One way to stay a taker for life is to inherit vast wealth. Any wealthy heir can live a life of leisure like a Peter Pan who never needs to work. Such a scion remains in a kind of dependency their entire life. In fact it is very hard to have a positive karmic balance sheet if you inherit billions of dollars because a vast inheritance gives tremendous power to consume without any necessity to ever make anything to give in return. Perhaps Jesus had this kind of taker in mind when he said it is as hard for the wealthy to enter the kingdom of heaven as for a camel to pass through the eye of a needle.
An evil taker is someone who does not reciprocate and takes from people who are unwilling to give. Evil takers steal what others have made using force, fraud, and/or stealth. Evil taking is pathological, but it is a part of life and we have all done it sometimes because we are all sinners. For most of history it was common to steal people’s labor by forcing them to make stuff through the institution of slavery.
Owning a natural resource like land is taking if the community is not sufficiently compensated.
Followers of Henry George argue that it is theft to own natural resources without compensating the rest of the community. People cannot make natural resources and most natural resources, including most of the privately-owned land in the world, were taken at some point in history by force, fraud, and/or stealth. Whereas the present owners likely paid fairly for the property, the chain of ownership always ultimately goes back to an original taking which taints the whole enterprise of owning the natural resources that God made. But regardless of how natural resources (like land) came to be owned, according to the Georgists, a natural resource should only be owned if the owner pays fair compensation, in the form of an annual tax (or rent), to everyone else who might have wanted to use it.
John Locke and his followers argue that people can own natural resources (like land) by mixing their labor with the natural resource, but the Georgists counter that people only own the value-added by their labor. Georgists believe that the underlying value of natural resources cannot be owned unless people pay an annual tax or rent to the community for the exclusive right to use the natural resource. So a building can be owned because it is mostly made by humans, but the land upon which a building stands should ideally be taxed to the point where it has no economic value. Then only the value-added–the building standing on the land–is worth owning.
The purest examples of a giver
The opposite of a taker is a giver, and pure giving is not going to make you wealthy. Some of our saints, like Mother Theresa, are as close as we can get to examples of pure givers who lived austere lives and tried every day to selflessly give as much as they could to help others. It is no accident that she called herself a “mother” because parents are always givers to their children.
Giving is a basis of family and church life and much military heroism. Anthropologists say that traditional-societies were mostly gift economies where people interacted based upon mutual giving rather than an exact accounting of debts and credits. So giving seems to have been the basis of most social interaction before the advent of hierarchical states. No society can survive without it and most giving is good for society. The one exception is when giving is one-sided AND encourages evil taking behavior in the recipient. It is harmful to both parties for a giver to develop a codependent relationship which enhances narcissistic sociopathic taking.
Reciprocation is always a mix of giving, taking, and symbiotic making
In addition to making or taking there is also a third way to get rich: reciprocating. Reciprocating involves making, taking, and giving all at once because reciprocating is an exchange whereby people make value by each both giving and taking. Reciprocation is so engrained in daily interactions that it is as hard to notice as a fish trying to explain water. There are many kinds of reciprocation, but here are two paradigmatic examples:
1. Market exchange: If I have some fruit that I value at $10 and my neighbor values at $22, then we can agree to reciprocal exchange. I’ll take money from him and give him the fruit which will make us both better off. For example, he could give me $16 which makes me $6 richer and he will get fruit that is worth $6 more to him than what he paid so we can both become $6 richer. We are both giving and taking and making value symbiotically. The exchange is symbiotically making $22-$10=$12 of symbiotic value.
2. Collective action: In the classic folktale of the Giant Turnip, Opah cannot pull the turnip out of the ground, so he asks Omah and even working together they cannot do it. So they keep asking a menagerie of characters to help until finally they ask a small mouse and with the mouse’s help working together with everyone else, they are finally able to pull up the giant turnip. Everyone gave to the communal effort to harvest the giant turnip and in the end, everyone can take a portion. Again, everyone in the story gives, and takes and makes symbiotic value. This is the reason why firms exist—people are usually more productive working together in a firm than working independently. In the folktale, Opah takes the leadership to coordinate the group’s work and some sort of hierarchical leadership is a typical organizational structure. Organizations are usually more productive at group tasks when there is some form of hierarchy with some people taking leadership roles to accomplish collective action and others following.
Reciprocation is hard-wired into the human psyche. It is why gratitude is a universal emotion. When someone does something nice for you, it generally causes you to feel some obligation to reciprocate in some way unless you have a narcissistic or antisocial personality disorder. Some people even believe that the universe itself operates on reciprocity. This is the idea behind karma and the maxim, “You reap what you sow.”
Because reciprocity always involves giving, taking, and symbiotic making, it is harder to analyze than any one of its three components. Adam Grant wrote a good book about it called Give and Take: Why Helping Others Drives Our Success, but he had a difficult time disentangling the different styles of reciprocity to pinpoint what is most successful. Most of the examples of successful “givers” in his book were successful because they were good at finding other “givers” who had a natural desire to reciprocate and avoided interacting with “takers.” Although “givers” only become rich when they reciprocate, Adam Grant warns that an excessive focus on reciprocation can be harmful. He recommends a spirit of giving because he says an excessive focus on ‘bean counting’ in our relationships is often harmful because it prevents optimal reciprocity. He calls an excessive focus on the tit-for-tat accounting of our interactions the “matcher” style of reciprocation. Matchers create relationships that are more transactional than emotional and emotional ties based upon warmth and respect are more powerful motivators of symbiotic reciprocity than transactional ties based upon a mental accounting of who is obligated to whom. The emotional ties of unconditional giving produce better relationships when everyone has a similar amount of emotional desire to give. Unsurprisingly, marriages that are based upon a conditional tit-for-tat exchange are less healthy than marriages based upon an emotional desire to give.
Reciprocation can lead to inequality because taking is part of reciprocating
Taking often happens due to unequal power where those with more power take from those with less power which exacerbates inequality. Although voluntary reciprocation should benefit each party involved, reciprocation can also lead to inequality because in every reciprocal exchange, there is always a tension between giving and taking. For example, in the market exchange example above where I have fruit that I value at $10, I could try to sell it to my neighbor for $22, and then I would be taking all of the value that is created in the exchange. In this reciprocal relationship, although I am not technically stealing because I am not leaving my partner worse off, I am taking all of the net benefit in the relationship, so I am giving nothing and taking all of the symbiotic value we make through trading. On the other hand, I could give the fruit to my neighbor for only $10 and then I am being a giver because even though I have lost nothing, I am giving him all of the value our relationship is creating symbiotically.
All governments take and reciprocate. Some are much worse than others.
We all reciprocate and we all have both a desire to give and a selfish desire to take, so it is often impossible to separate the three. For example, even the most sociopathic taker has a selfish motivation to reciprocate with other takers because a gang of takers can take a lot more by banding together than they can as individuals. Very few thieves live like hermits and reason most sociopaths prefer to live in societies is either because they can steal more “Giant Turnips” by banding together or because it is often easier to trade for what they want than to steal what they want and reciprocating enhances their selfish consumption.
Most anarchists believe that government is inherently a pure evil taker. Although this is wrong, they have a point in that most governments throughout history have been run by evil elites who reveled in taking from their people. But 99% of people are not anarchists because we are thankful that government provides public goods for society that increase our wellbeing by creating public health, safety, transportation infrastructure, education, a justice system for adjudicating and preventing disputes with takers. One of the benefits of modern constitutional democracies is to prevent evil elites from doing the kind of egregious taking that authoritarian nations typically experience.
Just like thieves benefit from reciprocating, governments do too and Mancur Olson explained why governments have even more incentive to reciprocate than roving thieves. Suppose there is a society in anarchy. In anarchy, selfish takers much more freedom to steal because there is no threat of police or jailtime. So the takers who are good at using violence to rape and steal will become roving bandits that plunder all they can from each maker household until there it nothing worth stealing and then they will move on to plunder the next maker.
But makers aren’t stupid and they are likely to band together to fight off takers and that is one way that a democratic government could arise. But takers aren’t stupid and they will also band together to overcome the maker communities. The takers have two advantages. First, the takers can devote all their resources to specialize in violence whereas the makers are also devoting time to making so the makers resources are divided unless they form a big enough government to hire full-time specialists in violence. Secondly, it is easier to destroy than to create (due to the second law of thermodynamics!) so takers always have the ability to threatening the makers with ruin because the makers have to invest in productive capital (tools, buildings, inventory, etc.) whereas the takers only need weapons as capital which are inherently more dangerous to try to take and/or destroy than a building or herd of animals.
For most of history, it was impossible for communities of makers to form a democratic government that was big enough to create enough military and police force to stop the roving bands of takers. In this case, then they will have a self-interest in asking the strongest roving bandit to stay put to defend them from other roving bandits. This is because a stationary bandit will have completely different incentives from a roving bandit in that a stationary bandit won’t want to steal everything from his people and destroy their capital goods because then there will be little to steal next year. A stationary bandit will want his people to not only survive, but thrive and build more capital goods so that there is more to steal next year. In fact, he will want to build public goods that make his people more productive in the future. It is his self-interest to reciprocate even if he is a narcissistic psychopath. This is what dictatorships are like. Even though a narcissistic dictator wants to take as much as possible, if he is sure he will be in power next year, then his selfishness leads him to reciprocate by investing his resources to create roads, hospitals, schools and other public goods that directly benefit his people to increase his future income. Most importantly, every government tries to constrain most of the evil takers in society. It only takes one evil taker to make everyone else miserable. A key role of government is to help us restrain those selfish impulses. We all have them to some degree, and a few people have them in psychopathic abundance.
Democracies have incentives that work better for the median person because the worst possible democracy is a dictatorships of the majority which maximize the wellbeing of the majority of the population (at the expense of a minority). This is better than a dictatorship because a dictator takes from everyone he can and that hurts the majority rather than a minority. Thus, democracies have the incentive to preserve more people’s property rights and provide public goods to a broader swath of society. A democracy operates with the consent of (at least) the majority which is a much greater equality of power than other forms of government.
The biggest problem of “democracy” is that most governments that claim to be democratic are not really very democratic because some smaller groups have power over the majority, but the more inclusively power is shared, the better the incentives for government to increase the wellbeing of a broader swath of people. (This is certainly true for the US where the electoral college regularly allows a minority to elect the president over the wishes of the majority and gerrymandering thwarts majority rule in congress and many other undemocratic features of our “democracy”.
Bargaining power determines individual earnings
Whether an exchange between two people is equally beneficial or whether one takes most of the symbiotic gains of exchange is determined by power differentials in the relationship. Organizational hierarchies are the main source of power differential which determines how resources are divided. For example, in the 1980s and ’90s, corporate CEOs gained more power in America and they started taking about 10 times more of the total revenues than before (relative to their average worker).
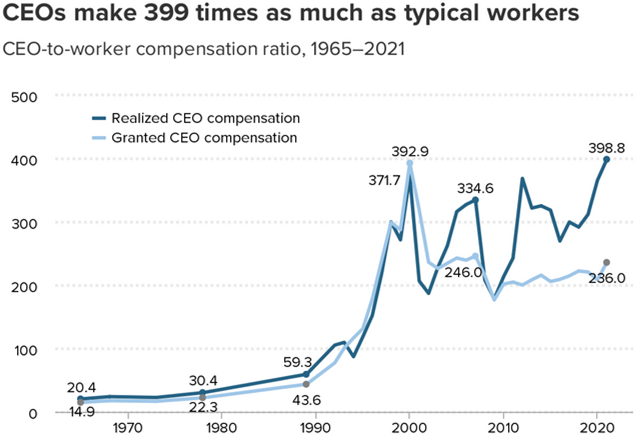
Then other interests got more power within corporations and dramatically cut CEO pay after the year 2000, and there has been a power tug-of war ever since with CEO pay jumping up and down relative to their workers (and their shareholders)!
Most critics of high CEO pay, like the authors of the above graph, complain that the CEOs are taking money away from workers. That that is true, but economic theory predicts that CEOs are mostly taking money away from their shareholders when CEOs dramatically raise their own pay. In the American system, corporate boards are legally supposed to represent the shareholders. Although American corporate boards reined in skyrocketing CEO pay in the 2000s, American CEOs still make much more money than foreign CEOs running the same kind of corporations because American CEOs have more influence over their boards and more power over their workers than CEOs in other countries where CEOs have less power over board members and workers have both more union power and more representation on boards. Social power determines why some CEOs can take a lot more than other CEOs in different times and places!
When people are working together in a team, it is impossible to say exactly how much each person makes because production is symbiotic. When one gear of a machine transfers energy to another gear, we cannot separate out how much of the machine’s production is done by any single gear because the machine would not work without all its gears and a machine requires all its parts to be useful. Any part that isn’t needed, isn’t really a part of the machine and is likely to be scrapped.
Similarly, every worker in an organization is like a cog in the machine. Saying that a CEO produces 10% of a corporations’ profit is as silly as saying that your brain produced 10% of your body’s success in winning a marathon. In reality, all the people within a corporation work symbiotically like the organs of your body. The CEO would produce nothing and the corporation would go bankrupt without the rest of the company’s workers just like your brain would die without the rest of your body’s organs. Productivity is only one of several factors that determine individual pay within organizations. Pay is distributed within a hierarchy according to how much bargaining power each person has. Productivity helps increase one’s bargaining power, but organizational politics determines who is in different levels of power in the hierarchy and hierarchical power is more important for determining pay than productivity.
Another quality that gives workers bargaining power is the ability to sabotage the company. The CEO has tremendous sabotage ability and this helps explain high CEO pay. Nobody else in a corporation could make it lose money faster than its CEO and with that ability comes great bargaining power. Unions get bargaining power from another kind of sabotage ability: the ability to strike which is the ability to sabotage the company’s profits. Other than CEOs and a few other powerful employees, most workers do not have much ability to sabotage their organization and so most workers get most of their bargaining power from their opportunity cost. Your opportunity cost is what you would get paid in your next best job. So a taxi driver in New York City gets paid many times more money than a taxi driver in Guatemala not because the New York driver is more productive at driving, but because the New York driver could be working in another industry (like a factory) where workers really are many times more productive than Guatemalan workers. New York taxi drivers are also able to take more from their riders because their average rider is more productive than the average rider in Guatemalan taxis and so American passengers have a greater ability to pay higher taxi fares.
So American taxi drivers are richer than Guatemalan taxi drivers not because of differences in the productivity of individual drivers, but because of differences in how much bargaining power drivers have to take money from their riders. American taxi drivers have more bargaining power because they have a higher opportunity cost — they could be working in highly productive jobs which pay well. The opportunity cost wage is a backstop which prevents taxi driver wages from falling below that level.
Finally, another important reason why some people earn more than other individuals is their luck to gain ownership over valuable stuff that they didn’t create. God made all natural resources and yet rich people get much of their income from owning stuff like land that God made. When Steve Jobs died, the main reason why Bill Gates was over 6 times richer was not that Gates had been 6 times more productive. Gates earned more money because he had more bargaining power & luck which got him 6 times more ownership of corporate value that had been produced by thousands of people. By every other measure than wealth, Jobs was a far more productive entrepreneur than Gates.
In a meritocratic world, people’s pay would be determined by their productivity, but we cannot measure individual productivity when people’s work is interdependent. I think everyone agrees that difference in income are usually not perfectly explained by productivity differences and it is differentials in bargaining power and ownership of scarce resources that explains the fact.
Some inequalities of power are useful for increasing the wellbeing of societies because they provide useful incentives that motivate productivity. Other power inequalities reduce social wellbeing because they incentivize takers to use their power to perpetuate their power like the elites who want to perpetuate an aristocracy of inheritance for their codependent heirs.
Making mainly determines why some nations are richer than other nations.
Above I gave examples showing that productivity differences (making) does not explain most of the differences between how much different individuals earn. For each person, our income is mostly determined by the productivity of the people that we reciprocate with and our bargaining power vis-à-vis those people. Individual productivity helps increase bargaining power, but other factors like hierarchical power are much more important.
But it is the productivity of nations and not their bargaining power that mostly explains why some nations are richer than other nations. Whereas it is impossible for a prosperous individual be self-sufficient (like a hermit), large nations are relatively close to self-sufficiency. Small nations are usually very far from self-sufficient and extremely interdependent with many trading partners, but small nations have very little hierarchical power over other nations, so they do not have much power to be takers and must reciprocate for everything they get. So differences in the productivity of nations explains most of the differences in the income of nations because there isn’t much taking relative to total GDP.
GDP is the most popular international measure of total national income. Big nations mostly produce their own income and import a small share of GDP. None of the nations with GDP larger than the Netherlands have imports that are worth more than 43% of GDP. Very few of the nations of the world have imports that are smaller than 20% of GDP, but all three of the biggest economies in the world have imports that are less than 20% of GDP. The three biggest are Japan, China, and the US, shown on the bottom right side of the graph, in order from left to right.
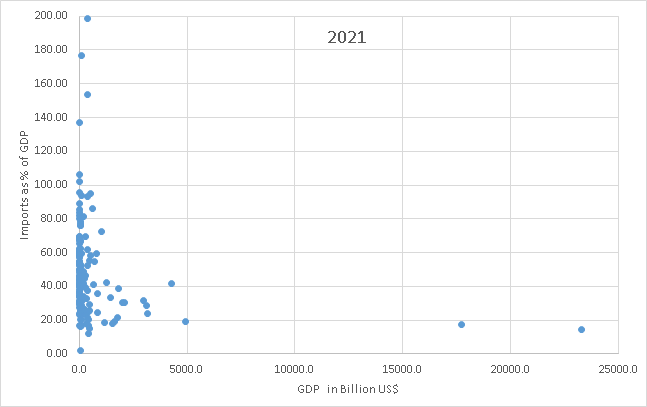
Whereas small countries cannot possibly be prosperous without a lot of foreign trade, large countries have to be relatively self-sufficient because the bigger the nation, the fewer outsiders there are to interact with and the more the insiders. For example, suppose a single country took over the entire world. That country could not trade at all and could only get wealthier by increasing productivity. The wealth of the world is solely determined by the productivity of the world because there is nobody else to take from. Using up natural resources could boost consumption temporarily, but it destroys wealth because natural resources are a form of wealth and whereas spending down wealth can feel like income, it is really just a temporary consumption boost that is stealing from the future.
The US, China, and Japan are so large that their economies cannot primarily rely upon taking resources from other nations. That is why their imports are relatively small at less than 20% of their income (GDP). Furthermore, that 20% is a reciprocal relationship and although it is impossible to say whether the symbiotic gains of trade are divided equally, most nations probably reciprocate about the same value that they import. Most of the reciprocation is in the form of exports but there is also reciprocation through selling off national assets and/or international borrowing for later reciprocation plus interest. Large nations also give a small amount of international aid like the recent support for Ukraine. This is pure gift without expectation of reciprocation, but it is only a small amount of income. Gift outflows are usually less than half of one percent of GDP, so it is very small compared with reciprocation. So most nations today probably take approximately 0% of GDP from other nations (in net) because of strong reciprocity in modern international trade.
All individual humans start out life as takers during our long childhoods. Although nations do not have a childhood, if you go back far enough, the history of most nations also full of an extraordinary amount of taking too. Empires, by definition, are extreme takers that constantly plotted to send armies to steal from other nations. They stole precious metals, slaves, land, and anything else they could profitably exploit. Colonialism was the last major phase of many millennia of conquests and then colonialism abruptly started unravelling. Since World War II, most nations have discovered that it is less profitable to take than to reciprocate because war is bad for business and it is more profitable to trade with foreign people than to try to steal their lands. As a result, wars of conquest have greatly diminished for the first time since the dawn of history. There are still some pariah nations that explicitly try to build empires of conquest, like Russia repeatedly invading Ukraine, but today it is harder to get rich by taking through force than it was in previous centuries.
The last era when nationalist taking was profitable was the colonial era but colonialism became increasingly unprofitable in the 20th century, as colonial possessions started to cost more money than they generated. Russia’s conquest of Ukraine is an excellent example that demonstrates how unprofitable imperialist wars are nowadays. Russia could have increased its prosperity by reciprocating with her neighbors instead of by spending vast amounts of resources attempting to take over her neighbors by force.
Tragically, Russia is controlled by an absolute dictator who cares more about his personal power than the prosperity of his people and he is willing to sacrifice the lives of hundreds of thousands of people and trillions of dollars of their resources in order to expand his imperial power over a small, impoverished neighboring country. Even if he eventually succeeds at conquering Ukraine, it will be a hollow victory because he will have conquered a broken nation he just destroyed. He will never be able to steal enough resources from Ukraine to make the invasion profitable for Russia. He would have earned far more prosperity by reciprocating with Ukraine and keeping Russia open for business with the entire world.
Indeed, the biggest punishment the West imposed on Russia was to withhold reciprocation. The trade sanctions the West imposed are a kind of economic warfare that is painful for both the West and Russia. Unfortunately, Russia has managed to soften the blow by dramatically increasing reciprocation with China, Iran, India, and other nations that do not care enough about the Ukraine invasion to sacrifice their profitable trading with Russia.
Why are automobile workers paid more?
If you are working on a car assembly line, how are you going to get paid more? You can either take more or make more.
You could take more by unionizing so you can take from management & owners (and the owners are already unionized to take from the workers, so it only seems fair to try to band together to fight back). Or the company could take more from customers by monopolizing a car market which increases power.
Alternatively you could make more cars per worker.
Why do car workers earn a lot more today than 50 years ago? The power of unions has declined so it is mainly because car workers are making a LOT more cars per worker AND they are making much better cars. In the 1970s, 2 million Americans produced 9 million cars which was 4.5 cars per worker per year and they were bad cars. In contrast, Chinese workers made only about 1 car/year and they were much worse quality. Today there are about 1.9 million automobile workers producing 12.86M cars per year and which is about 6.8 vehicles produced per worker per year. That includes all workers in the business and if you just include assembly-line workers, they make 73 vehicles per worker!
And American cars are incredibly much better today than in the 1970s. In the 1970s cars had:
- Average MPG ≈ 13–14 MPG (1970).
- Odometers turned over at 100k because manufacturers didn’t expect them to last that long! Japanese automakers began introducing 6‑digit odometers in the mid‑1980s, since they had longer lifespans.
- Typically rusted out well before their engines died.
- No air conditioning.
- Uncomfortable bench seats in front.
- Unsafe at any speed although the new safety innovation was to require three-point seat belts for front seat passengers in 1968 which were quite uncomfortable because they were rigidly fixed and prevented you from being able to lean forward at all.
So car makers make more cars today that get more than double the gas mileage and last twice as long and have numerous features that make them more valuable than cars in the past and that is why our car assembly-line workers get paid more. They would get paid even more if unions were able to extract a larger share of profits.
Conclusion
The four modes of economic interaction are giving, making, taking, and reciprocating. The latter three all increase one’s wealth. Although giving does not increase one’s selfish wealth, it is essential for the human species because it is the basis of family and without giving, no babies would ever have survived. So giving is an inherent human instinct which is important for the most important human relationships and the human species would perish without it. Neglect giving at your peril!
The main way that large groups of people (like nations) get rich today is by making. Reciprocation (trade) is also important for national prosperity, but the gravity equation of trade demonstrates that nations that make more also reciprocate more. This is different from the way most wealthy individuals get so rich. Individual inequality within hierarchical economic networks like firms and nations is explained by differences in both bargaining power and individual productivity. People with higher productivity generally have more bargaining power, but income is only partially related to individual productivity because individual wealth is almost completely interdependent with other people. Individual productivity is impossible to measure in organizations because co-worker productivity is symbiotic like the productivity of the organs of your body. So a big reason some people earn vastly more than others is more power to take more of their group’s production.
The main reason wealthy elites are wealthy is because of their ability to take from the community that they live in. Without a community to reciprocate with and take from, no person would be wealthy. For example if a wealthy person like Bill Gates lost all the other people in the world, (like in the TV series, The Last Man on Earth) he would suddenly have to live like an impoverished hermit who has to solely rely upon what he can make rather than what he can take. For a while he would be able to take goods that other people had previously made, but food eventually spoils and nothing could replace the services of countless laborers that we all use on a daily basis. Wealthy individuals are much more dependent on taking the labor of other people than the rest of us.
Most of us (except hermits) would also be poorer if all the other people in the world suddenly disappeared (perhaps in a rapture!), but the poorest people in society would see their material standard of living rise for a time. For example, imagine if the homeless people awoke one morning and everyone else disappeared from the planet. They could each take over their own mansion and gorge on all the food and drinks they find in the pantries and stores. However, even most homeless people would eventually be worse off without the rest of society once the stored food spoils or when inevitably they need services, like medical care, that are no longer available.